Leveraging Redis for online feature lookup
Redis, a popular in-memory data structure store, serves as a critical component in the infrastructure of machine learning systems, enabling fast lookups of features required for online inference.
In the last few days, I was facing a interesting challenge while working on feature lookups from a Redis datastore for online inference. Although the initial setup appeared to be straightforward, it quickly became evident that the lookup performance was far from ideal, with the response time increasing significantly over time.
I will use this TIL to share some of the findings from going through the code in the Redis client I was using, particularly the asynchrounous cluster implementation of the client (this is worth mentioning as it seems that there were a few merges of different clients into a single official one along the way).
Everything was going to the moon 🚀 🌕
After deploying the application to production, I soon realized that pretty much everything was going to the moon, not only from the app’s perspective but also within the Redis cluster - this included everything from the response time, to the cluster CPU usage and, most importantly, the number of connections.
While I was expecting a significant increase in connections after the app’s startup, what happened was that the number of connections continued to grow exponentially, even after the app had stabilized. This was particularly concerning, as the number of connections was not only impacting the app’s response time but also the Redis cluster itself (which was used by multiple clients). Within a couple of hours the count of connections was two to three times higher than the original count.
What is the Redis client doing under the hood?
The first thing that was worth understanding was basically why the hell was the client doing under the hood that allowed the app to create so many TCP connections. Equally important was understanding why these connections were persisting even when they were no longer required. After digging into the code it was clear why this was happening.
-
First things first, for each Redis command, what happens is that the client tries to acquire a connection from the connection pool. If there’s a connection available, all good; otherwise it just creates a new connection.
-
Second, there was no default max connections allowed per client, or maybe better, there was one but a really large value (2^31). This means that each client could, in theory, create as many TCP connections as they want, at least until the server starts complaining. If, for some reason, the client would reach the max connections allowed, a
MaxConnectionsErrorwould have been raised.
With that said, there were 2 issues that had to be solved here:
- too many connections are being acquired for each request.
- a lower max connections value should be set.
Too many connections being acquired for each request
During online inference, it is common for machine learning models to retrieve multiple features from an online feature store. This scenario applied to our situation as well. The thing is that if we performed individual operations for each of the 10 required features, we would need to request 10 separate connections from the pool for every single inference request.
Instead what we should be doing is pipelining all the requests and acquire a single connection from the pool to run them all.
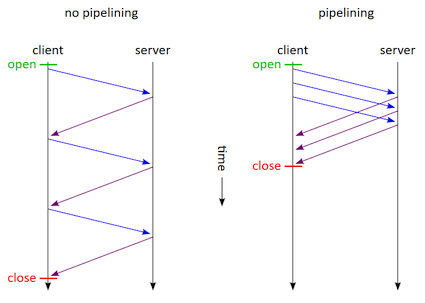
By leveraging Redis pipelining we are improving the performance by ensuring that multiple commands are sent to the cluster without waiting them individually (and sequentially), while at the same time ensuring that we are not jeopardizing the number of connections created as otherwise it would grow exponentially, impacting the app’s response time and the Redis cluster usage (e.g. CPU and memory) too.
Limit the max connections per pool
The next step would be to set the max connections per node in the pool to a lower value. However this one also ended up being quite tricky, as when the max connections in the pool is reached, the client doesn’t (asynchronously) wait for a connection in the pool to be free and ready for use, instead it raises a MaxConnectionsError leaving it up to the app to handle the error and determine the appropriate course of action.
Interestingly, the client does have connection error handling implemented. However, rather than simply retrying the operation, it takes a different approach. It closes all existing connections and recreates them from scratch. While this strategy might be beneficial in certain scenarios (as illustrated in this example), it proves to be less advantageous in our case, particularly considering the significant cost involved in establishing TCP connections for multiple nodes within the cluster.
Instead the solution was to leverage something like aioretry. This approach ensures that even in the unlikely scenario of having a client with a connection pool already filled to capacity (i.e., all active connections reaching max_connections) and all of them being currently in use, the operation gracefully waits in an asynchronous manner until a connection from the pool becomes available for use.