Spark architecture
Apache Spark is a distributed processing platform used for big data workloads. It is usually used for data or machine learning pipelines that require processing large amounts of data.
Spark’s architecture includes several components, which we will describe next.
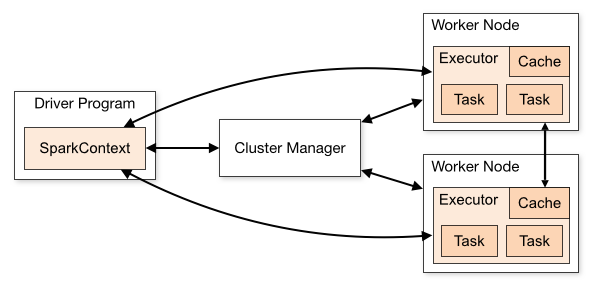
Driver Program
When creating and running a Spark application, it starts by running in the driver machine, e.g. your own machine. However, in order to fully leverage Spark, applications need to run as a set of independent processes in a cluster, as this is what enables the distributed processing and horizontal scaling we need for big data. One of the main responsibilities of the driver’s program is to create a Spark Context.
Spark Context
Running distributed work across a cluster requires some coordination - e.g. telling each cluster node what it should run and the resource allocation needed - this is why we need the Spark Context. The Spark Context connects to a Cluster Manager to acquire Executors to run the different Tasks that are part of our Spark application. Executors need our Spark application’s code to do the job, so this is also one of the Spark Context’s responsibilities.
Cluster Manager
Spark is agnostic to the Cluster Manager - the most common ones are Spark’s own standalone cluster, YARN, and Kubernetes. The Cluster Manager’s responsibility is to communicate with Worker Nodes to acquire Executors, which will be shared with the Spark Context.
Worker node
Spark’s goal is to distribute work across multiple machines so that any system can horizontally scale when facing large amounts of data - those machines are called Worker Nodes. Each Worker Node can have multiple Executor processes depending on the application requirements, e.g. if there are enough cores or memory.
Executor
Executors are the processes responsible for actually doing the work, they are assigned a partition of data and a Task by the Spark Context, and their responsibility is to make sure the task is successfully executed within the partition. For the sake of simplicity let’s consider the example of counting how many words each line has, on a large file with 1M lines and 10 Executors. In this scenario, each Executor would be responsible for processing 100k lines, and then the result would be aggregated and consolidated into a new file.
Each Executor can take advantage of multiple threads and will always run isolated from other processes (even if they are running within the same worker node).
Task
A Task is a unit of work sent to the Executor that should be applied to a partition of data. Tasks are part of Stages and DAGs, but those are interesting enough to have their own TIL.